Exploring Data With Pandas And Matplotlib
A brief run-down of this chapter in my book Data visualization with Python and JavaScript. This chapter uses Pandas and Matplotlib to drill down into our recently cleaned Nobel dataset, looking for interesting nuggets and narratives.
In the previous chapter, we cleaned the Nobel Prize dataset that we scraped from Wikipedia in. Now it’s time to start exploring our shiny new dataset, looking for interesting patterns, stories to tell, and anything else that could form the basis for an interesting visualization.
First off, let’s try to clear our minds and take a long, hard look at the data to hand to get a broad idea of the visualizations suggested. This is the form of the Nobel dataset, with categorical, temporal, and geographical data:
[{
'category': u'Physiology or Medicine',
'date_of_birth': u'8 October 1927',
'date_of_death': u'24 March 2002',
'gender': 'male',
'link': u'http://en.wikipedia.org/wiki/C%C3%A9sar_Milstein',
'name': u'C\xe9sar Milstein',
'country': u'Argentina',
'place_of_birth': u'Bah\xeda Blanca , Argentina',
'place_of_death': u'Cambridge , England',
'year': 1984,
'born_in': NaN
},
...
}]
The data suggests a number of stories we might want to investigate, among them:
- Gender disparities among the prize winners
- National trends (e.g., which country has most prizes in Economics)
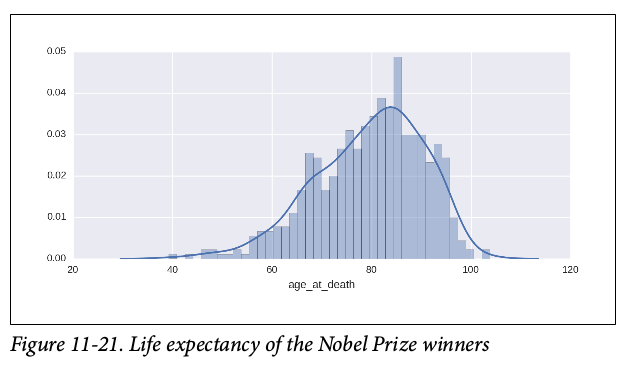
- Details about individual winners, such as their average age on receiving the prize or life expectancy
- Geographical journey from place of birth to adopted country using the +born_in+ and +country+ fields
These investigative lines form the basis for the coming sections, which will probe the dataset by asking questions of it, such as “How many women other than Marie Curie have won the Nobel Prize for Physics?”, “Which countries have the most prizes per capita rather than absolute?”, and “Is there a historical trend to prizes by nation, a changing of the guard from old (science) world (big European nations) to new (US and upcoming Asians)?”